1月17日,英国帝国理工大学团队 (Natsuko et al。)通过武汉出境人数及境外人数患病人数,对于武汉1月12日前患病人数进行了估计(1723人)。他们的逻辑非常简单,假设每个武汉市民随机进行国际旅行,那么从武汉出国的人中,患病的比例和武汉市市民患病的比例是相同的,通过国外确诊的人数,就可以反推出来武汉当时的患病人数。
这个方法看起来非常直接,但是有些很重要的因素不能被忽视,比如,中国2019年公民持有护照率只有13%,因此仅仅考虑海外病例对于整个武汉市情况的估计会有较大偏差。当然,在Natsuko et al。工作中,他们也对这种情况进行了讨论,他们声明,自己的研究是假设在每个武汉人出境的概率是独立的。但是此次疫情的起源地是武汉华南海鲜市场,地处汉口市中心,因此附近易感人群进行国际旅行的概率可能显著高于他们模型中所采用的1900万人武汉都市圈。 与此同时,根据疫情溯源研究,大多数最初病例都于华南海鲜市场的野味消费有关,而野味消费被认为是奢侈消费,相关人群高收入概率更高,也更有可能进行国际旅行。因此,这个模型的假设可能并不成立。
1月23日,帝国理工大学团队 (Natsuko et al。)又发布第二份报告,运用同样的模型将他们的预测从1月12日延伸至1月18日,计算出截至2020年1月18日可能有4000例患者。但是,1月10日开始的春运,以及从1月14日开始的机场火车站发热筛查,导致模型中的“机场覆盖人口”、“出境居民独立性”等假设被破坏严重,而第一份报告中的问题依旧保留,因此,用Natsuko模型对1月12-18日进行的估算准确度很低,几乎没有参考性。


江熹霖,基因组医学与统计学在读博士,牛津大学人类基因组中心 (Wellcome Centre for Human Genetics) & 牛津大学大数据中心 (Big Data Institute)
新型冠状病毒起源于武汉,因此估算武汉最初感染人群数量对于疫情分析有很大帮助。除了通过当地的医院具体病例排查外,通过其他侧面数据对感染人群数量进行预测也能够为掌握疫情情况提供支持。
1月17日,英国帝国理工大学团队 (Natsuko et al。)通过武汉出境人数及境外人数患病人数,对于武汉1月12日前患病人数进行了估计(1723人)。他们的逻辑非常简单,假设每个武汉市民随机进行国际旅行,那么从武汉出国的人中,患病的比例和武汉市市民患病的比例是相同的,通过国外确诊的人数,就可以反推出来武汉当时的患病人数。
这个方法看起来非常直接,但是有些很重要的因素不能被忽视,比如,中国2019年公民持有护照率只有13%,因此仅仅考虑海外病例对于整个武汉市情况的估计会有较大偏差。当然,在Natsuko et al。工作中,他们也对这种情况进行了讨论,他们声明,自己的研究是假设在每个武汉人出境的概率是独立的。但是此次疫情的起源地是武汉华南海鲜市场,地处汉口市中心,因此附近易感人群进行国际旅行的概率可能显著高于他们模型中所采用的1900万人武汉都市圈。 与此同时,根据疫情溯源研究,大多数最初病例都于华南海鲜市场的野味消费有关,而野味消费被认为是奢侈消费,相关人群高收入概率更高,也更有可能进行国际旅行。因此,这个模型的假设可能并不成立。
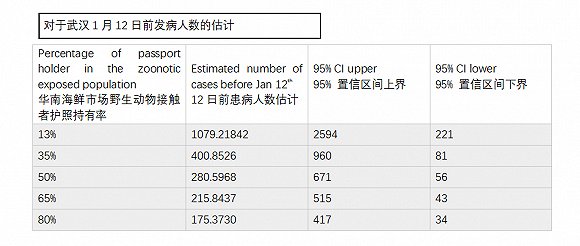
为了更精确地预测武汉最初发病人数,我们对Natsuko模型的进行了稳定性测试,假设武汉市区只有护照持有者才有可能进行国际旅行(这个是显然成立的),而非他们模型中假设的武汉都市圈1900万人都有相同概率进行国际旅行。当武汉华南海鲜市场易感人群有50%的持有护照时,根据Natsuko的模型,预测结果为1月12日前有281位感染者(95%置信区间56-671),而如果易感人群护照持有率为80%时,同样的预测结果为175人 (95% 置信区间 34-417)。而在原模型中,他们的推算结果为1月12日前武汉有1723名患者。这意味着目前的数据模型对于假设的依赖极强,估算的不确定性很大,甚至可能有10倍以上的误差。(见下表)
同时,该模型的核心数据是海外检出的3例病例,而这样小的样本会导致较大的置信区间,也就是预测的不确定性。在模型有高度不确定性的情况下,模型估计的范围上下可能有10倍以上的差距,用这样十倍以上偏差的结果来对疫情进行估计,实际指导意义并不大。
除此之外,在模型的检测窗口参数的选取上,他们使用的以往SARS及MERS-CoV的经验数据10天。而对于新型冠状病毒的研究显示,病毒的平均潜伏期为7天,中位数发作住院间隔为9天,因此使用16天作为检测窗口更加合适,而这也将导致原估计从1723调整至1079人。还有其他假设有待商榷,例如国内外检测手段的差别等,不再一一讨论,但以上均说明Natsuko模型的预测结果对于假设的依赖较强,而很多假设成立的可能性不大,因此预测的准确度有待进一步检测。
1月23日,帝国理工大学团队 (Natsuko et al。)又发布第二份报告,运用同样的模型将他们的预测从1月12日延伸至1月18日,计算出截至2020年1月18日可能有4000例患者。但是,1月10日开始的春运,以及从1月14日开始的机场火车站发热筛查,导致模型中的“机场覆盖人口”、“出境居民独立性”等假设被破坏严重,而第一份报告中的问题依旧保留,因此,用Natsuko模型对1月12-18日进行的估算准确度很低,几乎没有参考性。
值得注意的是,我们这里并不是断定帝国理工大学的预测结果可能偏高或偏低,而是仅仅说明其预测的准确度非常低,可能大幅偏高也可能大幅偏低。同时需要注意的是,目前疫情已经从武汉扩展到全国,且武汉的交通已经受到严格管控,而该预测模型是利用海外患者数量这个与当地疫情联系较弱的因子进行预测,同时预测的目标也仅仅限于武汉市(目前确诊的海外病例均与武汉市相关),从研究意义上,这个模型对于了解目前疫情全貌的帮助也有限。
从1月17日起,疫情已经扩散至其他省份, 而目前其他省份的确诊数量与地区与武汉交通关联密切程度直接正相关, 但湖北省内其他城市与武汉的交通关联度最高,却没有足够多的确诊报告。在目前阶段,基于各地医疗机构的实际数据(包括疑似病例数,疑似病例确诊率,就诊率等),结合春运前期的交通数据,对这些与武汉高度关联的城市的病情进行分析,对于掌握疫情整体情况是最为重要的,而非Natsuko模型这样利用相关系数较低的海外病例来对单个地区进行估测。
通过交通数据预测,湖北省内各市,河南、湖南的疫情可能被低估,有必要结合当地疫情数据及交通情况对这些区域的疫情进行测算。同时,鉴于交通关联性对于疫情扩散的显著作用,感染人数很可能在春运后半程有较大上升。测算交通压力带来的未来疫情变化,可能是目前流行病学计算的工作重心。